고등학교 인공지능 수학 수업자료 5 (영화별 유사도 분석, 콘텐츠 기반 필터링)
지난 시간 유사도 분석기 자료를 수정하여 사용자를 기반으로 분류하는 것이 아니라 영화를 기반으로 유사도를 재 분류해보자.
개인별 영화선호도를 성분으로하는 데이터의 행렬을 전환하면 영화를 초점으로 한 데이터를 얻을 수 있다.

지난 수업과 마찬가지로 영화명을 1행과 1열로 하는 표를 만들어 영화별 유사도를 분석할 수 있다.
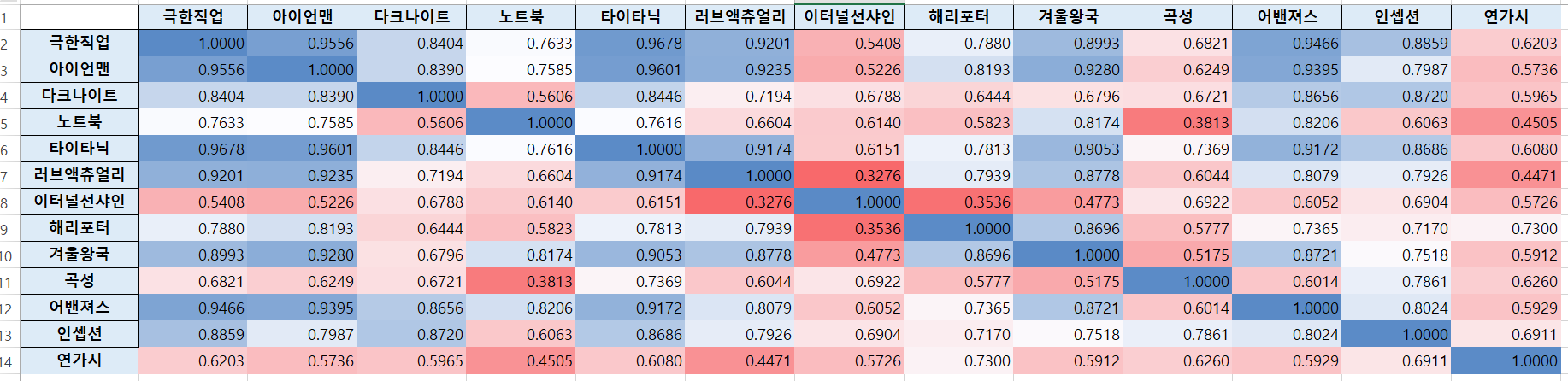
연수때 예시로 들 간단한 시연 용이었기에 영화를 13개만 선정했지만, 실제에서는 더 많은 항목에 대한 설문을 해서 자료를 모은다면 더 정교하게 유사도를 얻을 수 있을 것이다.
지난 시간에 다룬 사용자 기반의 유사도 분류는 과거 정보가 적은 사용자에 대해서 추천의 정확도가 떨어진다는 단점이 있는데 이렇게 콘텐츠를 기반으로 유사도를 분류하면 이런 점을 보완할 수 있다.
학기 초 다양한 학급의 학생, 혹은 온라인 쌍방향 수업을 한다면 다양한 학교의 학생들이 섞여서 수업을 듣게 될텐데 서로 다양한 주제에 대해 서로의 선호도를 조사하고 분류하게 된다면 나름 분위기 조성에도 도움이 될 만한 좋은 주제라고 생각한다.
다만 연수를 진행하며 발견한 문제는 보지 않은 영화를 0점으로 선택하게는 바람에 불필요하게 생기는 유사도의 차이다. 만약 내가 곡성을 안봤다고 0점이 선택되고 다른 사람이 곡성을 재밌게 봐서 5점을 선택했다면 둘을 유사도 계산에 넣기 보다는 무시하는 쪽이 더 좋겠다는 생각이 들었다. 이건 실제로 수업을 진행해 보며 코드를 수정해 봐야겠다.



댓글
댓글 쓰기